新闻公告
学院资讯
元
作者:365bet体育日期:2025/07/06 浏览:
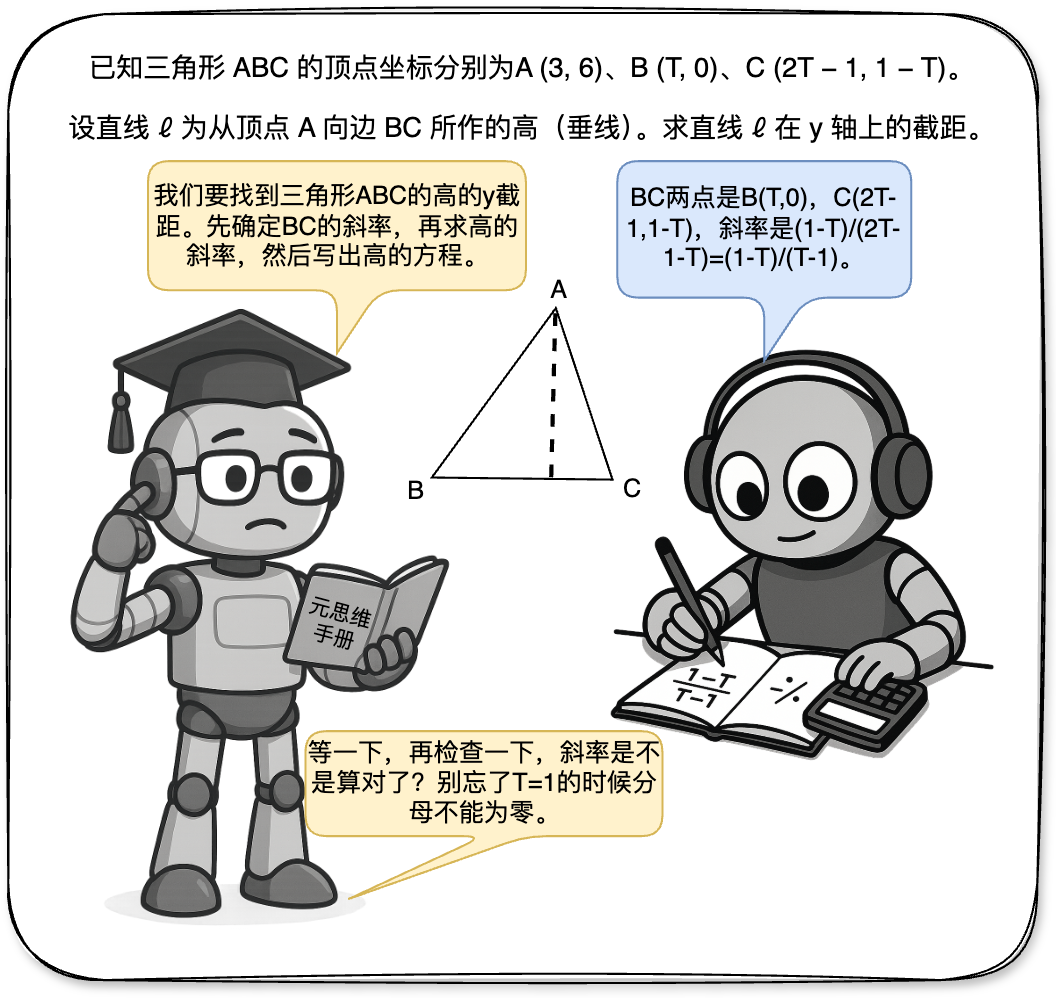 本文的第一位作者是上海北北大学的计算机科学医生的四年级学生Wan Ziyu。研究的主要方向是研究基本模型的加强和复杂推理。与上海北海大学人工智能学院和上海人工智能实验室的Hu Shuyue先生的 - 与 - 协会教授Wen Ying相对应。其他团队成员包括联合首先作家李·扬xiang,马克·施密特教授,宋杨教授,杨·莱尼教授和伦敦大学学院的王·朱尼教授,上海jiaotong大学的旺肖,王·汉吉教授和Zhang Weinan教授。引言最近,在大型推理模型时,在试验的试验法中出现了新的范式,包括①结构化搜索结(类似MCT),②奖励模型 + PPO流程 + PPO,③可验证的奖励 + GRPO(DEEPSEEKR1)。但是,大型模型何时产生的机制ES“ Ahamoment”尚不清楚。许多最近的研究表明,推理模式在推理能力上的重要作用。同样,这项研究认为,对大型模型的复杂理解的能力取决于元的能力。所谓的“荟萃扭转”是指监视,评估和控制其自己的推理过程,以实现更可调,有效的问题解决。这是完成代理完成长期复杂任务的必要方法。尽管大语言模型(LLM)表现出强大的推理能力,但如何实现像人类一样的更深入,更有条理的论点是一个主要的挑战。上图显示了两个机器人解决方案的一个示例,这些机器人找到了高线三角形的拦截,该机器人凭直觉显示了元与推理之间的劳动分裂:识别机器人进行计算,而元思维机器人则介入计划,崩解或校正关键节点。根据d在这一动机上,本研究提出了从多部位的角度进行建模和解决这个问题的建模,并确定了加强的元(Rema)剂的框架,该元素使用多元素之间的相互作用来对外部进行建模。 Title Title of Paper: Rema: Study Link Study Link Link Link: https://arxiv.org/abs/2503.09501github Code Link: https://github.com/ziyuwan/Rema-pubicyan, ang pagsasaliksik sa pagpapabuti ng kakayahang pang-iinip ay ang mga malalaking modelo ay pangunahing nahahati sa dalawang paraan:Pamamaraan: Ang pag-sampol at paghahanap para sa mga itinayo na data sa nakabalangkas na mga template ng pag-iisip ng meta para sa pangangasiwa at pag-aayos ng maayos, ngunit ang ganitong uri ng pamamaraan ay madalas na Pinapayagan Lamang Ang Modelo Na Tandaan Ang Sagot Na Ito ng ng ng ng ng ng ng ng ng ng ang a ang a ang likas na kakayahan ng pangangatuwiran na may na may kakayahang umangkop umangahang umangkap upang upang matuklasan ang ang pinaka ang pinaka ang pinaka-angaka-angaka-angangap na meta the Meta the Meta the Metaing Metains Model本身很难终极概括从分布中设定的问题;第二是DeepSeek R1型单位代理增强学习(SARL)的方法:通过引入相关的高质量数据获得了具有一些混合心理能力的基本模型后,该规则的奖励功能被使用rentProperer,研究加强研究以获得混合的元思考和详细的推理步骤。但是,这种方法通常依赖于强大的基本模型。对于功能不足的基本模型,在大规模的动作空间中无法很好地探索它们,也无需提及可能阅读和其他问题的不良能力。图1:将REMA框架与现有的大型模型复杂推理训练框架进行比较。为了应对这些挑战,雷玛框架采用了一种新的解决方案来分解理解两个层次代理的复杂过程:1。代理的元思想:负责制定战略管理和规划,宏观思维和指导,并反映和纠正对所需时刻感兴趣的当前的回归。 2。正义代理:负责根据Meta思维代理的指南进行详细的子TA,例如单步推理和特定计算。探索了这两个代理,并通过具有相似目标的学习加强的迭代过程进行学习。这种多代理系统(MAS)设计已扩展到许多代理中单位加固的勘探空间,使每个代理商在训练过程中都可以探索更具结构化和更好的探索。 Rema以这种方式平衡了一般驻留的能力与勘探效率的能力之间的权衡。 Meth Remathis研究的生成建模首先给出了愤慨的单一多代理思维过程(MAMRP)的含义。在单轮互动场景中,当给任务问题时,Meta的思维代理将进行宏分析和问题拆卸需要提出解决方案计划,而思想代理将根据逐步思考的说明来完成任务内容。具体而言,考虑到一个问题,元元思维代理首先给出了元思考,然后理解剂为问题提供了解决方案。该过程如下:在许多互动情况下,可以将Meta思维代理提供的元思维代理以更平等的方式添加到整个思维过程中。 Meta的思维代理可以清楚地计划,拆除,反思,回溯并纠正解决方案过程,其联系历史记录继续叠加直到完成。同样,这项研究可以给出许多MAMRP旋转的定义,如下所示:可以使用以下直接绘制图来理解整个系统的解决方案过程,考虑到两个代理,并且团队提高了奖励。通过 - 优化的两个代理 - 代理的重量:每个代理人奖励的奖励分别被视为一般答案及其正确的格式。为了更新方法,本研究使用当前的主要GRPO并增强++来节省视频记忆并加快训练。当多轮检查术语术语将扩展到许多周期场景,以提高系统的计算效率和可扩展性,团队已经进行了以下更改:(1)首先,它减少了通过共享两个模型参数的高架来维护两个模型参数的扩展,并简化突然突然突然突然突然模型参数的依赖性关系。具体来说,本研究使用系统及时的词来代表各种角色来代表不同代理的技术。在优化过程中,两个代理数据用于培训和更新参数。 (2)第二个是针对许多互动情况的加固研究s。与这项研究不同,每个周期的完整输出被定义为一个动作。正式化和剪切的损失是通过引入转交级比率(转交级比率)进行的。优化的具体目标如下:通过这种方式,在多次训练旋转过程中,可以消除令牌级别的损失,以获得长度偏差,此外,通过考虑一个周期中所有代币的整体作物,训练过程可以在一定程度上稳定。实验结果:单一REMA实验首先将Vanila(VRP)推理过程(VRP)与通用小屋进行比较,RL VRP_RL训练结果,MRP_RL在单轮设置中。该小组对数学推理的许多基准(例如数学,GSM8K,AIME24,AMC23等)和LLM-AS-AS-A-A-Gudge基准(例如RewardBench,JudgeBench)进行了许多基准(例如数学,GSM8K,AIME24,AMC23等)进行了广泛的REMA评估。在数学问题中,团队使用数学培训集(7.5K)进行培训,并且在LLM-A-A-A-Gudge工作中,奖励基地分为5K培训样本和970个在LLM-AS-A-A-Gudge工作领域进行培训和试验的示例。表1:比较单一REMA实验的结果表明,在许多脊柱干预训练模型中,REMA继续在平均表现出所有基线方法(例如Llama-3-8B结构,Llama-3.1-8B教学,QWEN2.5-7B-INTSTRUCT)。尤其是在数据集分发的数据库中,Rema在大多数基准测试中实现了最佳性能,这完美地反映了Meta的思维机制带来的巨大遗传概括能力。例如,使用具有MA3-8B - 实施者模型的AMC23数据集中的性能的LLAANG改进,最多可达20%。消融实验证明,向REMA引入多年龄系统在实践推理能力方面很有用,该团队已经进行了学习研究的实验两个在一个周期下。问题1:元是否可以考虑为推理剂的加强剂研究吗?该团队分别比较了三种强化训练技术。基地的RL使用主模型直接执行RL训练; SFT的RL在RL培训开始之前使用GPT-4O专家数据作为启动;在META的心中,RL使用形成FromGPT-4O的心理药物来提供RL培训中的高水平指南。图3显示了训练过程中不同水平的三个测试集准确性变化的趋势。实验结果证明,元思维会影响促进识别模型增强的研究,尤其是在更艰巨的任务中。问题2:LLM可以通过研究加强来改变不同的想法吗?图4:培训研究研究研究研究研究的元思维剂。然后,小组探索了元思维研究的研究研究不同尺度的代理,团队设计了一套含义的动作。通过让模型的输出操作以JSON格式(首先MDETERMINE(ROT,RETRITE,RETAIL)的类型(然后),然后 - 输出相应的内容),我们可以实现监视模型动作类型的输出。图4显示了与三种类型的训练动作一致的问题难度的变化。实验发现,在小型模型(Llama3.2-1b-教学)中进行训练时,元思维方法迅速转换为输出简单方法,即“不要做任何事情”。虽然可以根据问题的难度轻松选择各种元思考的动作(例如Llama3.1-8B-Instruktura)稍大的模型(例如Llama3.1-8B-Instruktura)。该结果还意味着,自主的快速和缓慢选择现在吸引越来越多的关注的问题可以在一定程度上有效地解决。许多Rema的多循环中的实验5许多Rema结束的结果,团队已扩展到许多设置设置以进行实验。首先,由于大多数语言模型本身都无法通过许多对话周期破坏问题,因此该团队首先将800个多轮MAMRP的示例从豪华轿车数据集中转换为冷数据开始,然后在SFT之后加权以进行加强学习训练。图5显示了数学水平训练曲线3-5(8.5K)和七个测试组的平均准确性。团队发现了以下结论:1。多个REMA训练周期可能会进一步改善训练集,但改进测试集并不明显。 2。这种做法是不道德的,对MGA超参数敏感。不同的采样设置(单一令牌的最大数量和最大对话数量)将具有不同的培训趋势。图5显示了上一篇文章中提出的两个改进的影响(共享参数更新和第二个比率与许多比率培训,团队是一个小型数据集,其中包含所有类型的问题,可以在此处观察收敛的速度和算法效率的示例。在不同采样设置下的实验结果均表明该方法可以有效提高样品效率。总而言之,该团队尝试了一种新的复杂推理范式,也就是说,使用两个分层代理在提升材料的过程中清楚地认识了Meta的思想,并激励他们通过研究加强来协作复杂的任务。该团队在实验的单轮和许多旋转中取得了一些结果,但是通过许多骑自行车训练,训练下降的问题需要更加解决。它表明,基于确定性MDP的当前培训过程可能不适用于随机/非平稳的MDP,并且此类问题的数据和模型需要更多探索。
本文的第一位作者是上海北北大学的计算机科学医生的四年级学生Wan Ziyu。研究的主要方向是研究基本模型的加强和复杂推理。与上海北海大学人工智能学院和上海人工智能实验室的Hu Shuyue先生的 - 与 - 协会教授Wen Ying相对应。其他团队成员包括联合首先作家李·扬xiang,马克·施密特教授,宋杨教授,杨·莱尼教授和伦敦大学学院的王·朱尼教授,上海jiaotong大学的旺肖,王·汉吉教授和Zhang Weinan教授。引言最近,在大型推理模型时,在试验的试验法中出现了新的范式,包括①结构化搜索结(类似MCT),②奖励模型 + PPO流程 + PPO,③可验证的奖励 + GRPO(DEEPSEEKR1)。但是,大型模型何时产生的机制ES“ Ahamoment”尚不清楚。许多最近的研究表明,推理模式在推理能力上的重要作用。同样,这项研究认为,对大型模型的复杂理解的能力取决于元的能力。所谓的“荟萃扭转”是指监视,评估和控制其自己的推理过程,以实现更可调,有效的问题解决。这是完成代理完成长期复杂任务的必要方法。尽管大语言模型(LLM)表现出强大的推理能力,但如何实现像人类一样的更深入,更有条理的论点是一个主要的挑战。上图显示了两个机器人解决方案的一个示例,这些机器人找到了高线三角形的拦截,该机器人凭直觉显示了元与推理之间的劳动分裂:识别机器人进行计算,而元思维机器人则介入计划,崩解或校正关键节点。根据d在这一动机上,本研究提出了从多部位的角度进行建模和解决这个问题的建模,并确定了加强的元(Rema)剂的框架,该元素使用多元素之间的相互作用来对外部进行建模。 Title Title of Paper: Rema: Study Link Study Link Link Link: https://arxiv.org/abs/2503.09501github Code Link: https://github.com/ziyuwan/Rema-pubicyan, ang pagsasaliksik sa pagpapabuti ng kakayahang pang-iinip ay ang mga malalaking modelo ay pangunahing nahahati sa dalawang paraan:Pamamaraan: Ang pag-sampol at paghahanap para sa mga itinayo na data sa nakabalangkas na mga template ng pag-iisip ng meta para sa pangangasiwa at pag-aayos ng maayos, ngunit ang ganitong uri ng pamamaraan ay madalas na Pinapayagan Lamang Ang Modelo Na Tandaan Ang Sagot Na Ito ng ng ng ng ng ng ng ng ng ng ang a ang a ang likas na kakayahan ng pangangatuwiran na may na may kakayahang umangkop umangahang umangkap upang upang matuklasan ang ang pinaka ang pinaka ang pinaka-angaka-angaka-angangap na meta the Meta the Meta the Metaing Metains Model本身很难终极概括从分布中设定的问题;第二是DeepSeek R1型单位代理增强学习(SARL)的方法:通过引入相关的高质量数据获得了具有一些混合心理能力的基本模型后,该规则的奖励功能被使用rentProperer,研究加强研究以获得混合的元思考和详细的推理步骤。但是,这种方法通常依赖于强大的基本模型。对于功能不足的基本模型,在大规模的动作空间中无法很好地探索它们,也无需提及可能阅读和其他问题的不良能力。图1:将REMA框架与现有的大型模型复杂推理训练框架进行比较。为了应对这些挑战,雷玛框架采用了一种新的解决方案来分解理解两个层次代理的复杂过程:1。代理的元思想:负责制定战略管理和规划,宏观思维和指导,并反映和纠正对所需时刻感兴趣的当前的回归。 2。正义代理:负责根据Meta思维代理的指南进行详细的子TA,例如单步推理和特定计算。探索了这两个代理,并通过具有相似目标的学习加强的迭代过程进行学习。这种多代理系统(MAS)设计已扩展到许多代理中单位加固的勘探空间,使每个代理商在训练过程中都可以探索更具结构化和更好的探索。 Rema以这种方式平衡了一般驻留的能力与勘探效率的能力之间的权衡。 Meth Remathis研究的生成建模首先给出了愤慨的单一多代理思维过程(MAMRP)的含义。在单轮互动场景中,当给任务问题时,Meta的思维代理将进行宏分析和问题拆卸需要提出解决方案计划,而思想代理将根据逐步思考的说明来完成任务内容。具体而言,考虑到一个问题,元元思维代理首先给出了元思考,然后理解剂为问题提供了解决方案。该过程如下:在许多互动情况下,可以将Meta思维代理提供的元思维代理以更平等的方式添加到整个思维过程中。 Meta的思维代理可以清楚地计划,拆除,反思,回溯并纠正解决方案过程,其联系历史记录继续叠加直到完成。同样,这项研究可以给出许多MAMRP旋转的定义,如下所示:可以使用以下直接绘制图来理解整个系统的解决方案过程,考虑到两个代理,并且团队提高了奖励。通过 - 优化的两个代理 - 代理的重量:每个代理人奖励的奖励分别被视为一般答案及其正确的格式。为了更新方法,本研究使用当前的主要GRPO并增强++来节省视频记忆并加快训练。当多轮检查术语术语将扩展到许多周期场景,以提高系统的计算效率和可扩展性,团队已经进行了以下更改:(1)首先,它减少了通过共享两个模型参数的高架来维护两个模型参数的扩展,并简化突然突然突然突然突然模型参数的依赖性关系。具体来说,本研究使用系统及时的词来代表各种角色来代表不同代理的技术。在优化过程中,两个代理数据用于培训和更新参数。 (2)第二个是针对许多互动情况的加固研究s。与这项研究不同,每个周期的完整输出被定义为一个动作。正式化和剪切的损失是通过引入转交级比率(转交级比率)进行的。优化的具体目标如下:通过这种方式,在多次训练旋转过程中,可以消除令牌级别的损失,以获得长度偏差,此外,通过考虑一个周期中所有代币的整体作物,训练过程可以在一定程度上稳定。实验结果:单一REMA实验首先将Vanila(VRP)推理过程(VRP)与通用小屋进行比较,RL VRP_RL训练结果,MRP_RL在单轮设置中。该小组对数学推理的许多基准(例如数学,GSM8K,AIME24,AMC23等)和LLM-AS-AS-A-A-Gudge基准(例如RewardBench,JudgeBench)进行了许多基准(例如数学,GSM8K,AIME24,AMC23等)进行了广泛的REMA评估。在数学问题中,团队使用数学培训集(7.5K)进行培训,并且在LLM-A-A-A-Gudge工作中,奖励基地分为5K培训样本和970个在LLM-AS-A-A-Gudge工作领域进行培训和试验的示例。表1:比较单一REMA实验的结果表明,在许多脊柱干预训练模型中,REMA继续在平均表现出所有基线方法(例如Llama-3-8B结构,Llama-3.1-8B教学,QWEN2.5-7B-INTSTRUCT)。尤其是在数据集分发的数据库中,Rema在大多数基准测试中实现了最佳性能,这完美地反映了Meta的思维机制带来的巨大遗传概括能力。例如,使用具有MA3-8B - 实施者模型的AMC23数据集中的性能的LLAANG改进,最多可达20%。消融实验证明,向REMA引入多年龄系统在实践推理能力方面很有用,该团队已经进行了学习研究的实验两个在一个周期下。问题1:元是否可以考虑为推理剂的加强剂研究吗?该团队分别比较了三种强化训练技术。基地的RL使用主模型直接执行RL训练; SFT的RL在RL培训开始之前使用GPT-4O专家数据作为启动;在META的心中,RL使用形成FromGPT-4O的心理药物来提供RL培训中的高水平指南。图3显示了训练过程中不同水平的三个测试集准确性变化的趋势。实验结果证明,元思维会影响促进识别模型增强的研究,尤其是在更艰巨的任务中。问题2:LLM可以通过研究加强来改变不同的想法吗?图4:培训研究研究研究研究研究的元思维剂。然后,小组探索了元思维研究的研究研究不同尺度的代理,团队设计了一套含义的动作。通过让模型的输出操作以JSON格式(首先MDETERMINE(ROT,RETRITE,RETAIL)的类型(然后),然后 - 输出相应的内容),我们可以实现监视模型动作类型的输出。图4显示了与三种类型的训练动作一致的问题难度的变化。实验发现,在小型模型(Llama3.2-1b-教学)中进行训练时,元思维方法迅速转换为输出简单方法,即“不要做任何事情”。虽然可以根据问题的难度轻松选择各种元思考的动作(例如Llama3.1-8B-Instruktura)稍大的模型(例如Llama3.1-8B-Instruktura)。该结果还意味着,自主的快速和缓慢选择现在吸引越来越多的关注的问题可以在一定程度上有效地解决。许多Rema的多循环中的实验5许多Rema结束的结果,团队已扩展到许多设置设置以进行实验。首先,由于大多数语言模型本身都无法通过许多对话周期破坏问题,因此该团队首先将800个多轮MAMRP的示例从豪华轿车数据集中转换为冷数据开始,然后在SFT之后加权以进行加强学习训练。图5显示了数学水平训练曲线3-5(8.5K)和七个测试组的平均准确性。团队发现了以下结论:1。多个REMA训练周期可能会进一步改善训练集,但改进测试集并不明显。 2。这种做法是不道德的,对MGA超参数敏感。不同的采样设置(单一令牌的最大数量和最大对话数量)将具有不同的培训趋势。图5显示了上一篇文章中提出的两个改进的影响(共享参数更新和第二个比率与许多比率培训,团队是一个小型数据集,其中包含所有类型的问题,可以在此处观察收敛的速度和算法效率的示例。在不同采样设置下的实验结果均表明该方法可以有效提高样品效率。总而言之,该团队尝试了一种新的复杂推理范式,也就是说,使用两个分层代理在提升材料的过程中清楚地认识了Meta的思想,并激励他们通过研究加强来协作复杂的任务。该团队在实验的单轮和许多旋转中取得了一些结果,但是通过许多骑自行车训练,训练下降的问题需要更加解决。它表明,基于确定性MDP的当前培训过程可能不适用于随机/非平稳的MDP,并且此类问题的数据和模型需要更多探索。相关文章
- 2025-10-0610月4日举行的“ Zhejiang Ba”比赛:杭州和
- 2025-10-05假期的第三天,比“四川超级”更热是在
- 2025-10-04塔切尔:贝林之所以被击败,是因为他没
- 2025-10-03奥斯卡以眼泪向中国超级联赛承认:没有
- 2025-10-02与大湾地区的Hunanese球队相比,Shaoyang的“